
During his time as a member of the .txtlab, Benjamin worked on a research project that quantifies the effects of corporate acquisition in local news. He assembled a dataset of over 130,000 news articles and built computational models of locality in news to study how acquisition alters the information environment of affected publications.
This research project began two summers ago under the supervision of Prof. Andrew Piper, Graduate Program Director of Digital Humanities. Prof. Piper noticed articles coming from sports publications that were purchased by a larger conglomerate were facing important cuts in staff and temporary hiatus. In this context, Benjamin and Prof. Piper began to wonder whether corporate acquisition had an impact on the staffing, resources, and content of local publications, especially since studies seem to give less attention to these publications.
To collect the dataset for this project, Benjamin and co-authors Kaitlyn Todd and Prof. Piper extracted articles from a target set of publications using web scraping. The corpus built through this method comprised approximately 130,000 articles from more than 30 publications. With this dataset, Benjamin et al. focused on two components for analysis. First, they sought to identify differences between the periods of pre and post-acquisition of these publications, all of which went through high-profile acquisitions and subsequent cuts. Second, they aimed to understand to what extent articles shared between publications under the same conglomerate were different from those that were not shared. The second analysis was especially relevant for corporate consolidation. For example, when scraping a set of 28 publications under the ownership of the same media conglomerate, Benjamin found a large number of duplicate articles—these publications were sharing articles with one another because they pertained to the same owner.
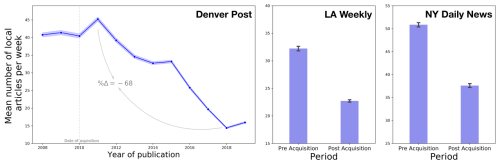
Given the scope of this research project, Benjamin et al.’s main interest was the role of locality concerning corporate acquisition. Thus, their analyses focused on mentions of locations. They employed name entity recognition to identify and analyze patterns concerning name entities referring to specific locations (i.e., country, city, businesses, landmarks, etc.). The locations mentioned in articles were later geocoded, that is, paired with specific locations on a map. The mapping process allowed Benjamin et al. to measure and visualize the closeness between these mentions and the city that the publication attempted to cover. Benjamin et al. then focused on classifying articles based on measurements of distance to understand whether the articles’ focus on locality changed before and after corporate acquisition. Benjamin mentions that they also considered other name entities, namely, people. He observes that local people were being mentioned at different rates before and after acquisition and that he was particularly interested in measuring the number of mentions of local, state, and national politicians as the period pre and post-acquisition unfolded.
In the final stage of analysis, Benjamin et al. sought to identify discourse patterns, that is, whether the articles in the dataset had a more national focus (as opposed to local focus) following corporate acquisition. The main question they asked was whether there were characteristics that publications incorporated to approach the style of national publications. To explore this question, they built a corpus of national publications and compared the distribution of words of both datasets to test whether distributions of local and national publications were approaching each other following acquisition.
Measuring locality
Web scraping was a fundamental method for Benjamin et al. to collect their data:
“Access is an important factor. Students and researchers with similar projects should choose publications that can be easily scraped.”
Benjamin also recommends diving into the field of research. In the case of this project, he explains that journalists have been covering the acquisition phenomena for some time and that he decided to follow journalists, choose from what they were already covering, and build upon their observations and findings. Benjamin et al.’s project was adjusted as more cases were being covered.
One of the main challenges for Benjamin during this research project relates to measures of locality. Benjamin explains “it is hard to translate locality into computational models that you can apply to large amounts of articles. It is hard to put the ‘feeling’ of an article being ‘local’ into actual characteristics. It is especially difficult to develop a rough definition of what makes an article ‘local.’” In this regard, Benjamin mentions there are necessary trade-offs in defining the local: “there is often a trade-off between interpretability and complexity in computational models, and a good example of this trade-off is in the models of locality we used. In the definition-based model of locality, we explicitly stated the features we were using to classify an article as local or non-local. However, this definition of local does not model all dimensions along which articles are local versus non-local. In contrast, in the model of locality, which compared the local publications to national publications, we did not have to commit to specific features in order to measure locality. Instead, an article was ‘local’ if its distribution was not close to the national publication distribution—local is defined as not national. The issue with this not national method, however, is that it does not tell us what specific characteristics of the articles have changed.”

Benjamin considers that one of the main contributions of this research project is drawing attention to a very serious issue that is already the focus of important discussions among journalists. In this sense, this project introduces a generalizable methodology that allows for a unique understanding of the phenomena and brings this type of analysis into conversations about corporate acquisition.
“Collecting and exploring data reveals patterns and consequences of corporate acquisition that might not have been noted before. The pattern of sharing, for example, only becomes visible if you collect the data. Visualizing such patterns has the power to spread information about real-life problems.”
From .txtlab to NiemanLab
Benjamin always wanted this research project to become an article. Benjamin et al. felt it was an important component of their work. Benjamin started the process of writing as the project was developing: “Writing helps identify gaps, plan future steps, and think through the project. Writing is not the last step; it is essential for the development of the project.”
After publishing their article in the journal New Media and Society, Benjamin surprisingly found an email in his junk folder from NiemanLab at Harvard inviting him and Prof. Piper to an interview. The interviewer had read the paper and was interested in learning more about the project and its findings. Here is where Benjamin notices the importance of publishing: “Getting your research out there is important. You should share your work beyond academia. In my case, I have been able to spread the message and draw more attention to this problem, which is a fundamental contribution of this project.” Benjamin also highlights the value of holding a conversation in environments other than academia. He values this experience as a way to be better prepared for different modes of approaching and presenting his research work. He believes it has taught him versatility in spreading knowledge production.
Doing DH at McGill
Benjamin is currently preparing to begin his MA in linguistics at McGill in the coming fall. He is interested in pursuing research at the intersection of computational linguistics and digital humanities. He sees great value in the overlapping of these disciplines to more widely understand important research questions. He envisions his MA research as being similar to this research project as the methods will likely overlap. In this sense, Benjamin defines digital humanities as
"The use of computational methods to study questions related to the humanities, and the study of how computational methods change how we can ask questions in the humanities."
Visit Benjamin’s personal website and learn more about his work in his paper in New Media and Society, co-authored with Kaitlyn Todd and Prof. Piper. Make sure to read their interview with NiemanLab as well!